 |
|
МЕНЮ
|
Реферат: Основные функции и компоненты ядра ОС UNIXПриведенное краткое обсуждение понятия нити кажется достаточным для того, чтобы понять, что внедрение в ОС UNIX механизма легковесных процессов требует существенных переделок ядра системы. (Всегда трудно внедрить в программу средства, для поддержки которых она не была изначально приспособлена.) Подходы к организации нитей и управлению ими в разных вариантах ОС UNIXХотя концептуально реализации механизма нитей в разных современных вариантах практически эквивалентны (да и что особенное можно придумать по поводу легковесных процессов?), технически и, к сожалению, в отношении интерфейсов эти реализации различаются. Мы не ставим здесь перед собой цели описать в деталях какую-либо реализацию, однако постараемся в общих чертах охарактеризовать разные подходы. Начнем с того, что разнообразие механизмов нитей в современных вариантах ОС UNIX само по себе представляет проблему. Сейчас достаточно трудно говорить о возможности мобильного параллельного программирования в среде UNIX-ориентированных операционных систем. Если программист хочет добиться предельной эффективности (а он должен этого хотеть, если для целей его проекта приобретен дорогостоящий мультипроцессор), то он вынужден использовать все уникальные возможности используемой им операционной системы. Для всех очевидно, что сегодняшняя ситуация далека от идеальной. Однако, по-видимому, ее было невозможно избежать, поскольку поставщики мультипроцессорных симметричных архитектур должны были как можно раньше предоставить своим покупателям возможности эффективного программирования, и времени на согласование решений просто не было (любых поставщиков прежде всего интересует объем продаж, а проблемы будущего оставляются на будущее). Применяемые в настоящее время подходы зависят от того, насколько внимательно разработчики ОС относились к проблемам реального времени. (Возвращаясь к введению этого раздела, еще раз отметим, что здесь мы имеем в виду "мягкое" реальное время, т.е. программно-аппаратные системы, которые обеспечивают быструю реакцию на внешние события, но время реакции не установлено абсолютно строго.) Типичная система реального времени состоит из общего монитора, который отслеживает общее состояние системы и реагирует на внешние и внутренние события, и совокупности обработчиков событий, которые, желательно параллельно, выполняют основные функции системы. Понятно, что от возможностей реального распараллеливания функций обработчиков зависят общие временные показатели системы. Если, например, при проектировании системы замечено, что типичной картиной является "одновременное" поступление в систему N внешних событий, то желательно гарантировать наличие реальных N устройств обработки, на которых могут базироваться обработчики. На этих наблюдениях основан подход компании Sun Microsystems. В системе Solaris (правильнее говорить SunOS 4.x, поскольку Solaris в терминологии Sun представляет собой не операционную систему, а расширенную операционную среду) принят следующий подход. При запуске любого процесса можно потребовать резервирования одного или нескольких процессоров мультипроцессорной системы. Это означает, что операционная система не предоставит никакому другому процессу возможности выполнения на зарезервированном(ых) процессоре(ах). Независимо от того, готова ли к выполнению хотя бы одна нить такого процесса, зарезервированные процессоры не будут использоваться ни для чего другого. Далее, при образовании нити можно закрепить ее за одним или несколькими процессорами из числа зарезервированных. В частности, таким образом в принципе можно привязать нить к некоторому фиксированному процессору. В общем случае некоторая совокупность потоков управления привязывается к некоторой совокупности процессоров так, чтобы среднее время реакции системы реального времени удовлетворяло внешним критериям. Очевидно, что это "ассемблерный" стиль программирования (слишком много перекладывается на пользователя), но зато он открывает широкие возможности перед разработчиками систем реального времени (которые, правда, после этого зависят не только от особенностей конкретной операционной системы, но и от конкретной конфигурации данной компьютерной установки). Подход Solaris преследует цели удовлетворить разработчиков систем "мягкого" (а, возможно, и "жесткого") реального времени, и поэтому фактически дает им в руки средства распределения критических вычислительных ресурсов. В других подходах в большей степени преследуется цель равномерной балансировки загрузки мультипроцессора. В этом случае программисту не предоставляются средства явной привязки процессоров к процессам или нитям. Система допускает явное распараллеливание в пределах общей виртуальной памяти и "обещает", что по мере возможностей все процессоры вычислительной системы будут загружены равномерно. Этот подход обеспечивает наиболее эффективное использование общих вычислительных ресурсов мультипроцессора, но не гарантирует корректность выполнения систем реального времени (если не считать возможности установления специальных приоритетов реального времени, которые упоминались в п. 3.1.2). Отметим существование еще одной аппаратно-программной проблемы, связанной с нитями (и не только с ними). Проблема связана с тем, что в существующих симметричных мультипроцессорах обычно каждый процессор обладает собственной сверхбыстродействующей буферной памятью (кэшем). Идея кэша, в общих чертах, состоит в том, чтобы обеспечить процессору очень быстрый (без необходимости выхода на шину доступа к общей оперативной памяти) доступ к наиболее актуальным данным. В частности, если программа выполняет запись в память, то это действие не обязательно сразу отображается в соответствующем элементе основной памяти; до поры до времени измененный элемент данных может содержаться только в локальном кэше того процессора, на котором выполняется программа. Конечно, это противоречит идее совместного использования виртуальной памяти нитями одного процесса (а также идее использования памяти, разделяемой между несколькими процессами, см. п. 3.4.1). Это очень сложная проблема, относящаяся к области проблем "когерентности кэшей". Теоретически имеется много подходов к ее решению (например, аппаратное распознавание необходимости выталкивания записи из кэша с синхронным объявлением недействительным содержания всех кэшей, включающих тот же элемент данных). Однако на практике такие сложные действия не применяются, и обычным приемом является отмена режима кэширования в том случае, когда на разных процессорах мультипроцессорной системы выполняются нити одного процесса или процессы, использующие разделяемую память. После введения понятия нити трансформируется само понятие процесса. Теперь лучше (и правильнее) понимать процесс ОС UNIX как некоторый контекст, включающий виртуальную память и другие системные ресурсы (включая открытые файлы), в котором выполняется, по крайней мере, один поток управления (нить), обладающий своим собственным (более простым) контекстом. Теперь ядро знает о существовании этих двух уровней контекстов и способно сравнительно быстро изменять контекст нити (не изменяя общего контекста процесса) и так же, как и ранее, изменять контекст процесса. Последнее замечание относится к синхронизации выполнения нитей одного процесса (точнее было бы говорить о синхронизации доступа нитей к общим ресурсам процесса - виртуальной памяти, открытым файлам и т.д.). Конечно, можно пользоваться (сравнительно) традиционными средствами синхронизации (например, семафорами, см. п. 3.4.2). Однако оказывается, что система может предоставить для синхронизации нитей одного процесса более дешевые средства (поскольку все нити работают в общем контексте процесса). Обычно эти средства относятся к классу средств взаимного исключения (т.е. к классу семафоро-подобных средств). К сожалению, и в этом отношении к настоящему времени отсутствует какая-либо стандартизация. Управление вводом/выводомМы уже обсуждали проблемы организации ввода/вывода в ОС UNIX в п. 2.6.2. В этом разделе мы хотим рассмотреть этот вопрос немного более подробно, разъяснив некоторые технические детали. При этом нужно отдавать себе отчет, что в любом случае мы остаемся на концептуальном уровне. Если вам требуется написать драйвер некоторого внешнего устройства для некоторого конкретного варианта ОС UNIX, то неизбежно придется внимательно читать документацию. Тем не менее знание общих принципов будет полезно. Традиционно в ОС UNIX выделяются три типа организации ввода/вывода и, соответственно, три типа драйверов. Блочный ввод/вывод главным образом предназначен для работы с каталогами и обычными файлами файловой системы, которые на базовом уровне имеют блочную структуру. В пп. 2.4.5 и 3.1.2 указывалось, что на пользовательском уровне теперь возможно работать с файлами, прямо отображая их в сегменты виртуальной памяти. Эта возможность рассматривается как верхний уровень блочного ввода/вывода. На нижнем уровне блочный ввод/вывод поддерживается блочными драйверами. Блочный ввод/вывод, кроме того, поддерживается системной буферизацией (см. п. 3.3.1). Символьный ввод/вывод служит для прямого (без буферизации) выполнения обменов между адресным пространством пользователя и соответствующим устройством. Общей для всех символьных драйверов поддержкой ядра является обеспечение функций пересылки данных между пользовательскими и ядерным адресными пространствами. Наконец, потоковый ввод/вывод (который мы не будем рассматривать в этом курсе слишком подробно по причине обилия технических деталей) похож на символьный ввод/вывод, но по причине наличия возможности включения в поток промежуточных обрабатывающих модулей обладает существенно большей гибкостью. Принципы системной буферизации ввода/выводаТрадиционным способом снижения накладных расходов при выполнении обменов с устройствами внешней памяти, имеющими блочную структуру, является буферизация блочного ввода/вывода. Это означает, что любой блок устройства внешней памяти считывается прежде всего в некоторый буфер области основной памяти, называемой в ОС UNIX системным кэшем, и уже оттуда полностью или частично (в зависимости от вида обмена) копируется в соответствующее пользовательское пространство. Принципами организации традиционного механизма буферизации является, во-первых, то, что копия содержимого блока удерживается в системном буфере до тех пор, пока не возникнет необходимость ее замещения по причине нехватки буферов (для организации политики замещения используется разновидность алгоритма LRU, см. п. 3.1.1). Во-вторых, при выполнении записи любого блока устройства внешней памяти реально выполняется лишь обновление (или образование и наполнение) буфера кэша. Действительный обмен с устройством выполняется либо при выталкивании буфера вследствие замещения его содержимого, либо при выполнении специального системного вызова sync (или fsync), поддерживаемого специально для насильственного выталкивания во внешнюю память обновленных буферов кэша. Эта традиционная схема буферизации вошла в противоречие с развитыми в современных вариантах ОС UNIX средствами управления виртуальной памятью и в особенности с механизмом отображения файлов в сегменты виртуальной памяти (см. пп. 2.4.5 и 3.1.2). (Мы не будем подробно объяснять здесь суть этих противоречий и предложим читателям поразмышлять над этим.) Поэтому в System V Release 4 появилась новая схема буферизации, пока используемая параллельно со старой схемой. Суть новой схемы состоит в том, что на уровне ядра фактически воспроизводится механизм отображения файлов в сегменты виртуальной памяти. Во-первых, напомним о том, что ядро ОС UNIX действительно работает в собственной виртуальной памяти. Эта память имеет более сложную, но принципиально такую же структуру, что и пользовательская виртуальная память. Другими словами, виртуальная память ядра является сегментно-страничной, и наравне с виртуальной памятью пользовательских процессов поддерживается общей подсистемой управления виртуальной памятью. Из этого следует, во-вторых, что практически любая функция, обеспечиваемая ядром для пользователей, может быть обеспечена одними компонентами ядра для других его компонентов. В частности, это относится и к возможностям отображения файлов в сегменты виртуальной памяти. Новая схема буферизации в ядре ОС UNIX главным образом основывается на том, что для организации буферизации можно не делать почти ничего специального. Когда один из пользовательских процессов открывает не открытый до этого времени файл, ядро образует новый сегмент и подключает к этому сегменту открываемый файл. После этого (независимо от того, будет ли пользовательский процесс работать с файлом в традиционном режиме с использованием системных вызовов read и write или подключит файл к сегменту своей виртуальной памяти) на уровне ядра работа будет производиться с тем ядерным сегментом, к которому подключен файл на уровне ядра. Основная идея нового подхода состоит в том, что устраняется разрыв между управлением виртуальной памятью и общесистемной буферизацией (это нужно было бы сделать давно, поскольку очевидно, что основную буферизацию в операционной системе должен производить компонент управления виртуальной памятью). Почему же нельзя отказаться от старого механизма буферизации? Все дело в том, что новая схема предполагает наличие некоторой непрерывной адресации внутри объекта внешней памяти (должен существовать изоморфизм между отображаемым и отображенным объектами). Однако, при организации файловых систем ОС UNIX достаточно сложно распределяет внешнюю память, что в особенности относится к i-узлам. Поэтому некоторые блоки внешней памяти приходится считать изолированными, и для них оказывается выгоднее использовать старую схему буферизации (хотя, возможно, в завтрашних вариантах UNIX и удастся полностью перейти к унифицированной новой схеме). Системные вызовы для управления вводом/выводомДля доступа (т.е. для получения возможности последующего выполнения операций ввода/вывода) к файлу любого вида (включая специальные файлы) пользовательский процесс должен выполнить предварительное подключение к файлу с помощью одного из системных вызовов open, creat, dup или pipe. Программные каналы и соответствующие системные вызовы мы рассмотрим в п. 3.4.3, а пока несколько более подробно, чем в п. 2.3.3, рассмотрим другие "инициализирующие" системные вызовы. Последовательность действий системного вызова open (pathname, mode) следующая:
Системные вызовы open и creat (почти) функционально эквивалентны. Любой существующий файл можно открыть с помощью системного вызова creat, и любой новый файл можно создать с помощью системного вызова open. Однако, применительно к системному вызову creat мы должны подчеркнуть, что в случае своего естественного применения (для создания файла) этот системный вызов создает новый элемент соответствующего каталога (в соответствии с заданным значением pathname), а также создает и соответствующим образом инициализирует новый i-узел. Наконец, системный вызов dup (duplicate - скопировать) приводит к образованию нового дескриптора уже открытого файла. Этот специфический для ОС UNIX системный вызов служит исключительно для целей перенаправления ввода/вывода (см. п. 2.1.8). Его выполнение состоит в том, что в u-области системного пространства пользовательского процесса образуется новый описатель открытого файла, содержащий вновь образованный дескриптор файла (целое число), но ссылающийся на уже существующую общесистемную структуру file и содержащий те же самые признаки и флаги, которые соответствуют открытому файлу-образцу. Другими важными системными вызовами являются системные вызовы read и write. Системный вызов read выполняется следующим образом:
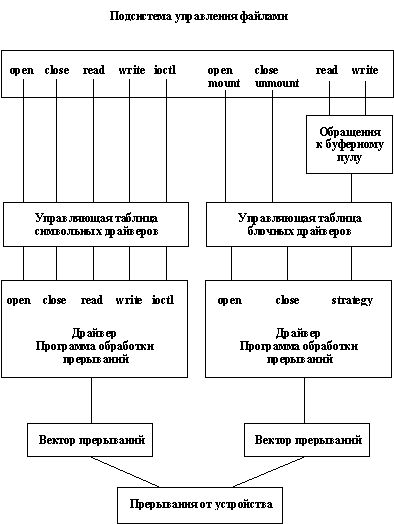
Операция записи выполняется аналогичным образом, но меняет содержимое буфера буферного пула. Системный вызов close приводит к тому, что драйвер обрывает связь с соответствующим пользовательским процессом и (в случае последнего по времени закрытия устройства) устанавливает общесистемный флаг "драйвер свободен". Наконец, для специальных файлов поддерживается еще один "специальный" системный вызов ioctl. Это единственный системный вызов, который обеспечивается для специальных файлов и не обеспечивается для остальных разновидностей файлов. Фактически, системный вызов ioctl позволяет произвольным образом расширить интерфейс любого драйвера. Параметры ioctl включают код операции и указатель на некоторую область памяти пользовательского процесса. Всю интерпретацию кода операции и соответствующих специфических параметров проводит драйвер. Естественно, что поскольку драйверы главным образом предназначены для управления внешними устройствами, программный код драйвера должен содержать соответствующие средства для обработки прерываний от устройства. Вызов индивидуальной программы обработки прерываний в драйвере происходит из ядра операционной системы. Подобным же образом в драйвере может быть объявлен вход "timeout", к которому обращается ядро при истечении ранее заказанного драйвером времени (такой временной контроль является необходимым при управлении не слишком интеллектуальными устройствами). Общая схема интерфейсной организации драйверов показана на рисунке 3.5. Как показывает этот рисунок, с точки зрения интерфейсов и общесистемного управления различаются два вида драйверов - символьные и блочные. С точки зрения внутренней организации выделяется еще один вид драйверов - потоковые (stream) драйверы (мы уже упоминали о потоках в п. 2.7.1). Однако по своему внешнему интерфейсу потоковые драйверы не отличаются от символьных.
Рис. 3.5. Интерфейсы и входные точки драйверов Блочные драйверыБлочные драйверы предназначаются для обслуживания внешних устройств с блочной структурой (магнитных дисков, лент и т.д.) и отличаются от прочих тем, что они разрабатываются и выполняются с использованием системной буферизации. Другими словами, такие драйверы всегда работают через системный буферный пул. Как видно на рисунке 3.5, любое обращение к блочному драйверу для чтения или записи всегда проходит через предварительную обработку, которая заключается в попытке найти копию нужного блока в буферном пуле. В случае, если копия требуемого блока не находится в буферном пуле или если по какой-либо причине требуется заменить содержимое некоторого обновленного буфера, ядро ОС UNIX обращается к процедуре strategy соответствующего блочного драйвера. Strategy обеспечивает стандартный интерфейс между ядром и драйвером. С использованием библиотечных подпрограмм, предназначенных для написания драйверов, процедура strategy может организовывать очереди обменов с устройством, например, с целью оптимизации движения магнитных головок на диске. Все обмены, выполняемые блочным драйвером, выполняются с буферной памятью. Перепись нужной информации в память соответствующего пользовательского процесса производится программами ядра, заведующими управлением буферами. Символьные драйверыСимвольные драйверы главным образом предназначены для обслуживания устройств, обмены с которыми выполняются посимвольно, либо строками символов переменного размера. Типичным примером символьного устройства является простой принтер, принимающий один символ за один обмен. Символьные драйверы не используют системную буферизацию. Они напрямую копируют данные из памяти пользовательского процесса при выполнении операций записи или в память пользовательского процесса при выполнении операций чтения, используя собственные буфера. Следует отметить, что имеется возможность обеспечить символьный интерфейс для блочного устройства. В этом случае блочный драйвер использует дополнительные возможности процедуры strategy, позволяющие выполнять обмен без применения системной буферизации. Для драйвера, обладающего одновременно блочным и символьным интерфейсами, в файловой системе заводится два специальных файла, блочный и символьный. При каждом обращении драйвер получает информацию о том, в каком режиме он используется. Потоковые драйверыКак отмечалось в п. 2.7.1, основным назначением механизма потоков (streams) является повышение уровня модульности и гибкости драйверов со сложной внутренней логикой (более всего это относится к драйверам, реализующим развитые сетевые протоколы). Спецификой таких драйверов является то, что большая часть программного кода не зависит от особенностей аппаратного устройства. Более того, часто оказывается выгодно по-разному комбинировать части программного кода. |
Copyright © 2012 г.
При использовании материалов - ссылка на сайт обязательна.